调度器就像一个发动机,如果没有了发动机输入动力,是无法正常运行的。
就像 Kubernetes 的调度器,它会负责根据节点的资源状态、Pod 的运行状态,判断 Pod 是调度到怎样的集群节点上去。对于 Karmada 这样的多云能力的调度器来说,调度能力也是大家非常关注的一个能力。
主要体现在,能不能通过调度的能力,将多集群的资源负载,控制在相对均衡的水位线,以及需要被调度的资源对象,以怎样的方式被调度到不同的集群上。
同时,调度器的可扩展能力,也是非常重要的,正常情况下只要调度器是足够成熟的,一般的场景也都会满足了,但是也会有一些是无法满足的,就像 Kubernetes 场景下的支持 GPU 的能力,大多数 GPU 的尝试都会扩展 Kubernetes 的调度能力。那接下来,我们就来看看 Karmada 的调度能力。
调度能力
Karmada 的调度能力主要包含两个方面,一个是调度策略,一个是调度时机。
调度策略是告诉使用者,调度器有哪些调度配置参数,可以提供使用和配置。
调度时机是调度器自身根据调度策略,决定在什么样的情况下,以那种调度方式处理调度策略,使用者无需关心。
调度策略
Depulicated
Depulicated:调度到所有集群的副本数保持和创建的 Deployment 副本数一致,最终的副本总数就是 Deployment 的副本数 * 集群数。这种调度的方式,没有任何动态计算集群可用副本数的逻辑在里面,也就是不会涉及 karmada-estimator 的调用。
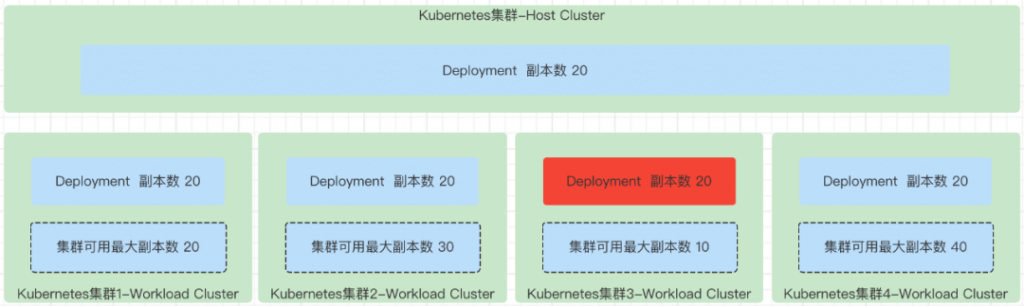

Divided
Divided:顾名思义就是拆分的意思,作用和 Duplicated 相反。
对于 Divided 类型的,其中又分为 weighted (按权重) 和 Aggregated 策略。
按权重分的又分为静态权重和动态权重。使用这种副本分配策略,会将创建 Deployment 的副本数作为总的副本数,根据策略的选择,拆分不同个数的副本到不同的集群上。
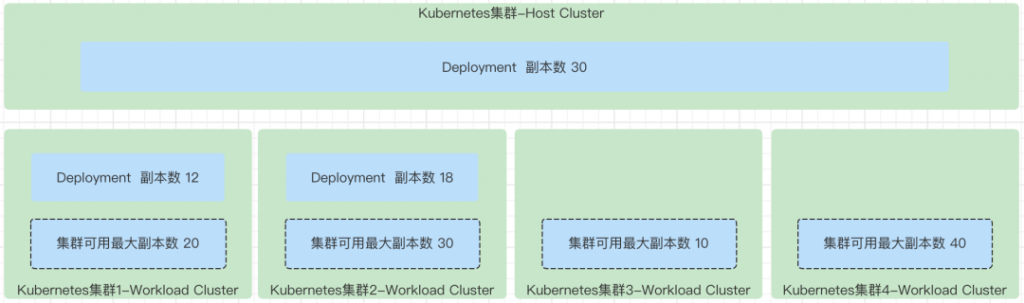
Aggregated
Aggregated:这是一种聚合调度策略,特性是调度的时候尽量紧凑一点。
举例如果有 5 个集群,同时第一个集群已经有足够的资源,可以运行所有的副本数,那就会把所有的 Pod 都调度在第一个集群上。因此,如果第一个集群不够,就会放一部分到第二个集群,但是剩下的集群不会有副本调度过去。扩缩容的时候,特性也是一致的。
这种调度策略会导致所有的集群的资源使用不均衡。
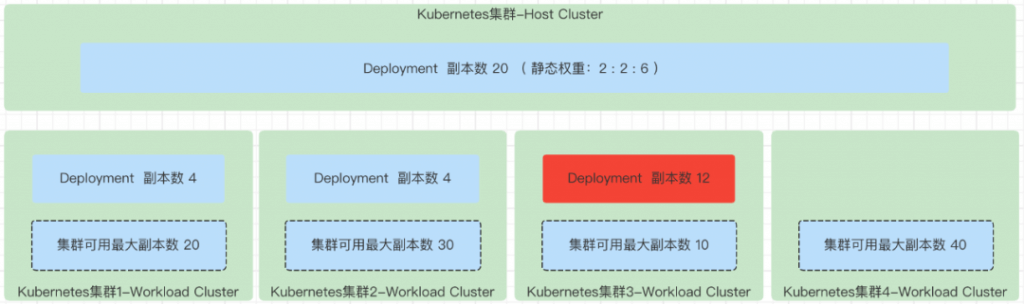
Static Weight
Static Weight:静态权重的分配副本的方式是需要在 PropagationPolicy 的 replicaScheduling 的部分设置相关策略。
权重的意思就是,根据所有设置的权重求和,得到权重和,然后每一个权重/权重和,也就是副本的分配比例,副本总数 * 对应的权重比例的个数,就是对应权重应该需要被分配的副本数。
注意这里会出现分配完之后,还有一点副本数没有被分配掉的情况,这个时候就是循环所有符合调度的集群,每一个集群一次分配一个副本的方式,直到所有剩下的副本数被分配完。
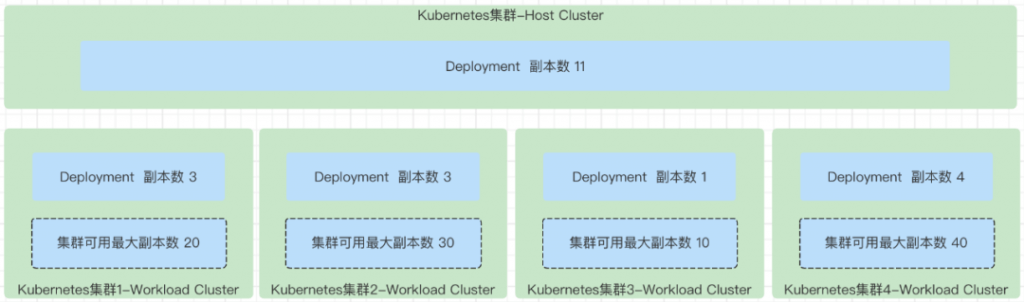
Dynamic Weight
Dynamic Weight:动态权重指的是,需要根据 karmada-estimator 计算的所有集群实时的可调度最大副本数,作为计算的参考。
举例,如有一个 Deployment 的副本数是 8,符合条件的集群有 2 个,第一个集群可调度的最大副本数是 10 个,第一个可调度的最大副本数是 6。那接下来动态权重的权重和就是 20+6=26。第一个集群的权重就是 20,第二个集群的权重就是 6,第一个集群应该被分配的副本数就是 8 * (20/26),第二个集群应该分配到的副本数就是 8 * (6/26)。注意这里会出现分配完之后,还有一点副本数没有被分配掉的情况,这个时候就是循环所有符合调度的集群,每一个集群一次分配一个副本的方式,直到所有剩下的副本数被分配完。
调度时机
FirstSchedule
当第一次创建资源对象的时候属于 FirstSchedule,修改资源对象触发的调度属于 ReconcileSchedule,但是这两种情况都是调用的相同的逻辑,都是调用的 scheduleOne() 这个方法。
- 根据 PropagationPolicy 中定义的 Placement 的 replicaSchedulingStrategy 定义,以及 ResourceBinding 的 Spec (包含资源对象,副本数) 和被选择的集群列表,去计算出哪些集群被调度,以及每一个集群被调度的副本数。
- 对于 Duplicated 类型的 ReplicaSchedulingPolicy,那就是所有集群被调度的副本数和资源对象定义的副本数是一直的 (如 Deployment 定义了 10,那就是每一个集群都应该被调度 10 个 Pod )。
- 对于 Divided 类型的,其中又分为 Weighted (按权重) 和 Aggregated 。按权重分的,又分为静态权重和动态权重。
- 对于静态权重,主要逻辑就是按照 Deployment 的总数,然后按比例进行分配,如果分配后还有剩余的没有调度,就每一个集群 +1 个的方式,平衡各个集群除了应该负责的权重以外的。
- 对于动态权重,分配的逻辑是计算出所有参与调度集群,能调度的最大 Pod 数量,注意这里计算的时候,是根据每一个集群的所有 node 去计算 Pod 的,所以会比较精确,至少保证计算出来的个数,是一定可以调度出去的,然后根据每一个集群的最大副本数,循环处理所有集群,累加集群的最大副本数,所有集群的最大副本数的累加和作为权重和,每个集群最大副本数作为权重来进行,最终的 Deployment 副本数的分配,这样的调度是比较均衡的,而且也是能最终保证副本可以调度出去。
- 对于 Aggregated 的,分配的逻辑是计算出所有参与调度集群,能调度的最大 Pod 数量,注意这里计算的时候是根据每一个集群的所有的 Nodes 的剩余资源,去计算 Pod 的资源需求,所以会比较精确,至少保证计算出来的个数是一定可以调度出去的,然后根据每一个集群的最大副本数,循环处理所有集群,累加集群的最大副本数,一旦这些集群的最大副本数的累加和满足了 Deployment 的副本数定义,就不在继续找集群了,所有最后的效果是可能 10 个集群,只需要前两个已经满足的集群参加调度,然后将这两个集群的最大副本数的累加和作为权重和,每个集群最大副本数作为权重,来进行最终的 Deployment 副本数的分配。
ReconcileSchedule
修改资源对象触发的调度属于 ReconcileSchedule,也是调用的 scheduleOne() 这个方法,逻辑和 FirstSchedule 一致,具体参见 FirstSchedule。
ScaleSchedule
修改资源对象的副本数触发的调度属于 ScaleSchedule,由 scaleScheduleOne() 方法完成具体的逻辑。
处理扩容的场景
扩容的时候,会根据上次调度的结果,也就是 ResourceBinding 中的 clusters,去 call karmada-estimator 去重新计算需要的副本数,在重新计算的时候,只是构建了一个需要扩容的副本个数,比如原来副本数是 5, 现在要扩容到 8,就是构建了一样的对象,只是副本数是 3,拿这个副本数是 3 的新的对象去重新计算需要调度到哪些集群中去,在所有的 ResourceBinding 中的 clusters 重新计算可用最大副本数。
preSelectedClusters 代表之前调度的时候,有哪些集群参与调度,可能会包含 [cluster name][0] 的情况。usedTargetClusters:代表是真正有 Pod 被调度到的集群。所以,usedTargetClusters 一般都是比 preSelectedClusters 包含的集群个数要少。举例:有调度的过程中,发现有 5 个集群是满足要求的,但是根据设置的 policy 的原因,在最后只调度来 2 个集群中,在这里 preSelectedClusters 就是 5,usedTargetClusters 就是 2,但是在设置 ResourceBinding 的 Spec 的 cluster 中设置的是 preSelectedClusters,只是有 2 个集群的副本数不为 0,有三个集群的副本数是 0。
对于 Aggregated 的类型,会拿 preSelectedClusters (可能会包含 [cluster name][0] 的情况) 去 karmada-estimator 重新计算,然后还是按照循环计算集群最大可用副本数,一旦够数了,就不再选择集群的方式,这样如果 usedTargetClusters 是排在前面的,就会尽量将新扩容出来的副本,都部署在已调度运行了 Pod 的集群上。但是在计算完成之后,对于 Aggregated 类型的,会首选优先选择已经运行了这个 Pod 的集群,具体做法就是将 preuserd (之前就有 Pod 在运行) 的集群尽量排到前面去。尽量将扩容出来的 Pod 也放到已经运行了该 Deployment 的 Pod 的集群中去,具体实现参见:presortClusterList()。
对于动态权重的类型,会拿 preSelectedClusters (可能会包含 [cluster name][0]的情况) 去 karmada-estimator 重新计算,然后按照所有 preSelectedClusters 的每一个集群的最大可用副本数作为权重总和,每一个集群的最大可用副本数作为集群权重,去按照权重分配副本数。这样下来还是会比较均衡。
对于静态权重的类型,还是拿着每个集群配置的权重去计算权重总和,然后按照每一个集群的配置的权重去分配副本数。
[CLUSTERA][0] 表示 CLUSTERA 没有被分配副本数,也就是不会被调度到 CLUSTERA 集群中去。
处理缩容的场景
对于缩容的操作,不会去 karmada-estimator 重新计算每一个最大可用副本数,而是就拿着 ResourceBinding 上次调度的完设置的 Spec 中的 clusters 作为 clusterAvailableReplicas。
对于 Aggregated 类型,就是拿着 Spec 中的 clusters 去计算,同时这个 clusters 中会包含 [cluster name][0] 的集群,在 Spec 的 clusters 中,副本数总和其实就是之前已经调度的,然后循环所有集群,累加每个集群已经调度的副本数的和,只要这个和已经满足现在的副本数要求,也就是被缩容的目标副本数,就 return,拿着已经满足的集群,按照原来处理 Aggregated 类型的逻辑,也就是每一个集群最大可用副本数的总和最为权重总和,每一个集群的最大副本数作为各自集群的权重,去分配需要调度到每一个集群的副本数,因为 Spec 中的 clusters 作为 clusterAvailableReplicas,所以最终的效果就是,缩容了之前每一个集群的副本数了,如果当原来是调度在两个集群中的,如果缩容的力度很大,有可能有一个集群的副本数就变成 0 了,也就是这个集群的 Deployment 的副本数变成 0 了。比如原来是 2 个集群,每一个集群分配了 5 个,总共 10 个,这个时候缩容成 2,这样第一个集群的 5 已经满足了 2 的要求,就会将第二个集群的 5 设置成 0,第一个集群的 5 设置成了 2。
对于动态权重类型,最后的效果就是,在之前已经调度的副本数不为 0 的集群上,都按照权重重新设置了更小的副本数了。这里权重的计算方式和所有的动态权重一样,只是 clusterAvailableReplicas 是拿的 spec 中的 clusters (上次调度的结果,这种情况一般不会出现 [cluster name][0] 的情况,除非有 3 个集群,需要调度的副本数 2,那就会有一个集群被分配的副本数是 0) 。当缩容的力度很大,也会出现原来有副本调度的集群,最后的副本被设置成 0 了,比如从 10 个副本,缩容 1 个副本。
对于静态权重类型,比较简单,就是按照固定的权重,用最新的副本数 (需要缩容到的副本数) 重新计算一下,计算完之后,每一个集群需要被调度的副本数就会变小,然后用这个副本数更新每一个集群的副本数,当力度很大,也会出现之前有 Pod 的集群,调度完就没有 Pod 了。比如从 10 缩容到 1。
[clusterA][0] 表示 clusterA 没有被分配副本数,也就是不会被调度到 clusterA 集群中去。clusterAvailableReplicas 表示某一个集群,根据 Pod 的内存,cpu 等,计算出最大可调度多少个这样的 Pod。
FailoverSchedule
当集群状态出现错误的时候,所触发的调度是属于 FailoverSchedule,特殊的地方在于,这种情况要想出发重新调度,首先是要打开 failover 的 feature gate 相关的 flag,同时还要设置 ReplicaSchedulingPolicy 才会触发副本被再分配。随着副本被再分配会触发 Work 对应的资源对象被修改,最后会在集群中修改资源对象的副本,达到再调度的能力。
至于为什么要 ReplicaSchedulingPolicy,参见 FailoverSchedule 本身这部分的第六点。
同时注意,ReplicaSchedulingPolicy 是静态权重的方式。由 rescheduleOne() 完成具体的逻辑。
变量说明
reservedClusters:代表已经调度出去的集群中,还有几个集群是健康的,剩下的这几个健康的,后面还是可以参与调度的。
availableClusters:目前健康的集群,但是又不在 reservedClusters 中,多指新增加的健康的集群 。
candidateClusters:对 availableClusters,使用插件的 filter 去判断一下,新加入的健康集群,是不是满足可以参与调度 。
delta :代表 Spec.cluster 中有几个是失败的集群。如果ReplicaScheduling 没有设置,或者调度的策略是 ReplicaSchedulingType,那新增加的集群,也就是 candidateClusters 集群个数,比 delta 少的话,就认定为可调度不足。
举例
第一次调度到了 cluster-1,cluster-2 ,cluster-3。
之后 cluster-1 的状态为不健康,这个时候 reservedClusters= "cluster-2 ,cluster-3"。
然后新增加了 2 个集群, availableClusters="cluster-4,cluster-5 "。
经过 filter 发现,cluster-4 不满足调度需求,那 candidateClusters = "cluster-5"。
最后得到可以参与调度的集群是:reservedClusters + candidateClusters = "cluster-2 ,cluster-3,cluster-5"。
最后返回的调度结果中,虽然包含了 "cluster-2 ,cluster-3,cluster-5",但是每一个集群的可调度副本数并没有设置。这样最后在 binding controller 的 ensureWork 中,会跳过调度器的调度结果,选择使用创建的 ReplicaSchedulingPolicy 策略去进行调度。现在只支持静态权重的方式,处理调度器不设置集群副本数的情况。getRSPAndReplicaInfos() 就是用来计算最后的副本分配的方法。计算的过程中拿 spec.clusters 去匹配 ReplicaSchedulingPolicy 中的 targetcluster,targetcluster 是一个 filter。
AvoidSchedule
上述的几种调度时机都不属于的情况下,就都属于 AvoidSchedule 类型,这种类型就是什么都不做。
内置插件
APIInstalled
检查被调度的集群是不是有适配的 Api Resource 支持。这里的校验数据就来源于 cluster 对象的 status 里的 Api Resource 部分。
ClusterAffinity
集群的粘性调度,因为集群对象本身是可以打标签的,要想调度到这些集群,需要设置相关的集群,类似 Kubernetes。
TaintToleration
集群的污点调度,因为集群对象本身是可以打污点的,要想调度到这些集群,需要容忍这些污点,类似 Kubernetes。
本文为转载文章,贵在分享,版权归原作者及原出处所有,如涉及版权等问题,请及时与我联系。
原文出处:墨天轮 - 容器魔方
原文链接:https://www.modb.pro/db/253265
 微信扫一扫
微信扫一扫  支付宝扫一扫
支付宝扫一扫